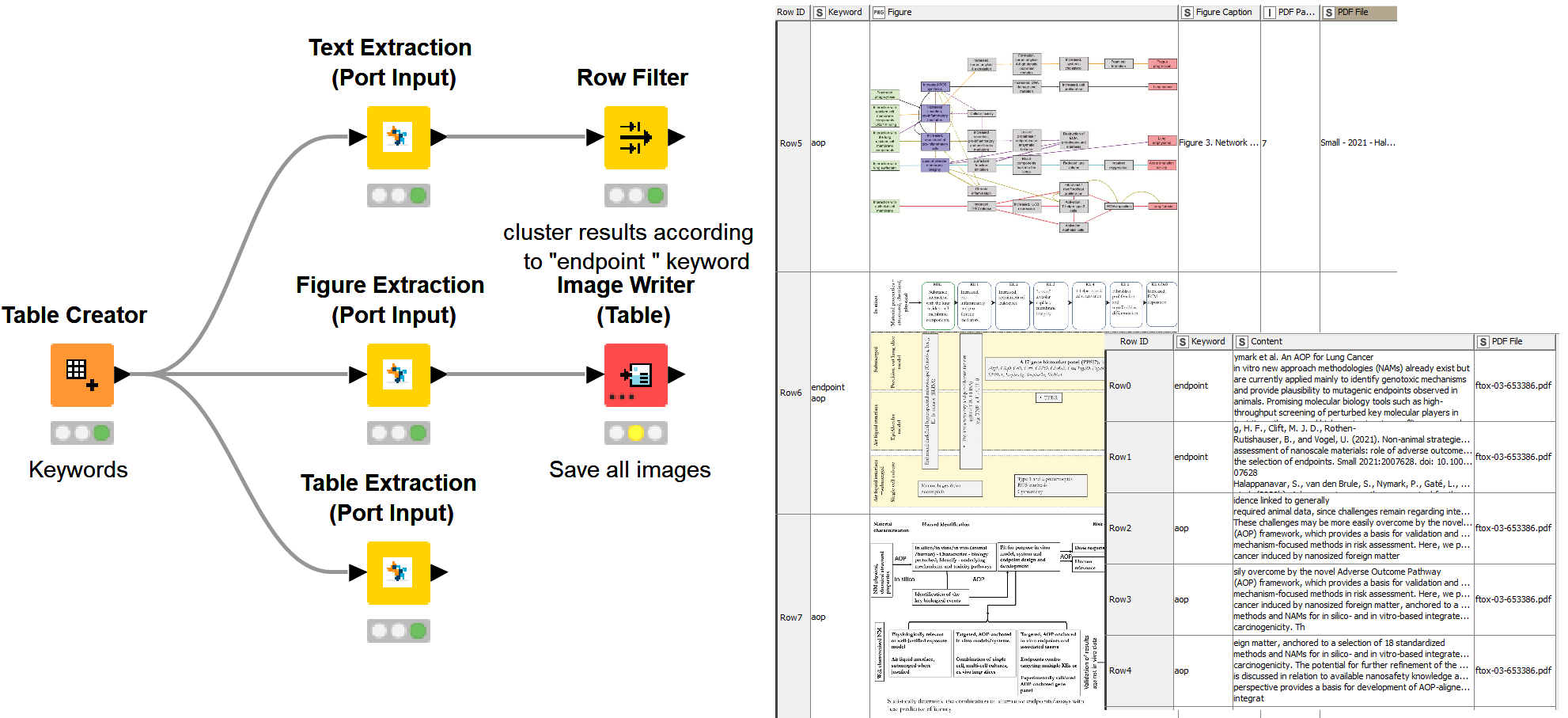
This node performs focused extraction of tables from one or more input PDF files. The background algorithm searches in the tables of the input file(s) for a list of keywords provided by the user.
Input The PDF files of iterest and a set of keywords
Output The node returns the tables that include one or more of the keywords and presents them in pure text format and in HTML or XML format.